
Abstract
Observing an action activates action representations in the motor system. Moreover, the representations of manipulable objects are closely linked to the motor systems at a functional and neuroanatomical level. Here, we investigated whether action observation can facilitate object recognition using an action priming paradigm. As prime stimuli we presented short video movies showing hands performing an action in interaction with an object (where the object itself was always removed from the video). The prime movie was followed by a (briefly presented) target object affording motor interactions that are either similar (congruent condition) or dissimilar (incongruent condition) to the prime action. Participants had to decide whether an object name shown after the target picture corresponds with the picture or not (picture–word matching task). We found superior accuracy for prime–target pairs with congruent as compared to incongruent actions across two experiments. Thus, action observation can facilitate recognition of a manipulable object typically involving a similar action. This action priming effect supports the notion that action representations play a functional role in object recognition.
Similar content being viewed by others

Introduction
Watching or imagining an action leads to an involvement of the observer’s motor system, that is, activates motor programs which are normally used to execute this particular action (for reviews see, e.g., Rizzolatti et al. 1996a; Jeannerod 2001; Rizzolatti and Sinigalia 2007; Graf et al. 2009). Moreover, action representations and representations of manipulable objects seem to be linked. For example, it has been shown that passively viewing, categorizing or naming manipulable objects evokes activity in cortical areas that are involved in processing action-related information (posterior parietal cortex, premotor cortex, middle temporal cortex) (e.g., Martin et al. 1996; Grafton et al. 1997; Chao et al. 1999; Chao and Martin 2000; Gerlach et al. 2002; Hoenig et al. 2008). Motor areas were also responsive when observers imagined interacting with an object (Decety et al. 1994), when they named words associated with an action (Martin et al. 1995) or when they retrieved knowledge about possible interactions with the object (Boronat et al. 2005). These findings suggest that processing manipulable man-made objects activates regions involved in processing motor- and action-related information even when the observer does not intend to act upon the object (see also Grèzes and Decety 2002). Moreover, perceiving manipulable objects automatically activates possible actions towards the object. Several behavioral studies demonstrate that the perception of a manipulable object can affect the execution of subsequent actions (Tucker and Ellis 1998, 2001, 2004; Glover et al. 2004). For example, Tucker and Ellis (2001) demonstrated that the execution of a motor response (power or precision grip) in a category decision task (natural versus man-made) was strongly affected by the size of the probe object. A power grip response was faster in response to a large object—affording a power rather than a precision grip—and inversely, precision grips were executed faster in response to small objects—even though object size itself is task-irrelevant. The perception of an object thus seems to automatically prepare for a subsequent action. Together, these observations suggest that action representations contribute to the representation of manipulable (man-made) objects such as tools or musical instruments.
In a recent study, Helbig et al. (2006) found evidence that action representations are also functionally involved in perception by demonstrating that action representations can facilitate object recognition. In this study, participants had to name briefly presented objects at the basic level of abstraction (e.g., hammer, drill). Naming accuracy was higher when the target object was preceded by a prime object that afforded a similar action (congruent condition), as compared to a condition in which prime and target object involved dissimilar actions (incongruent condition). Prime–target pairs in congruent and incongruent conditions were carefully matched for visual and semantic similarity (and other possible confounding factors) to ensure that the priming effect is not elicited by non-action-related stimulus features. The authors argued that the observed action priming effect is due to the pre-activation of action representations which can prime visual object recognition. However, action representations were not directly probed in this study. Participants viewed pictures of manipulable tools, but neither performed nor observed actions. In order to further substantiate the functional involvement of action representations in object recognition, it is therefore important to replicate action priming effects with more explicit action-related prime stimuli.
Hence, the present study was designed to investigate whether observing performed actions can prime visual object recognition. We used a picture–word matching task that required recognizing objects at the basic level of abstraction (e.g., Grill-Spector and Kanwisher 2005; Rosch et al. 1976).Footnote 1
As prime stimuli, we used movie clips displaying action sequences that were performed in interaction with an object. These movies only showed the hands performing the action; the objects that were involved in the actions were erased from the movies and hence not visible. Furthermore, the objects used to record the action movies were always different from the target objects and carefully matched for possibly confounding variables such as global semantic and shape similarity. As outlined above, considerable evidence demonstrates that observing an action elicits motor programs typically involved in the execution of this action (Rizzolatti et al. 1996a; Jeannerod 2001; Rizzolatti and Sinigalia 2007; Graf et al. 2009). The question arises whether an activation of these motor programs during action observation suffices to facilitate recognition of objects affording a similar action. Such a finding would further substantiate the proposed functional link between the action and perception systems (Helbig et al. 2006; Graf et al. 2009; see also Prinz 1990).
We therefore tested in two experiments whether object recognition is superior when the previously observed action in the prime movie is similar to the action typically afforded by the target object (congruent condition) in comparison to dissimilar actions (incongruent condition). It should be noted that in the congruent condition, the actions probed by the prime movies and the target objects were only similar, but never identical. Hence, a mere effect of action repetition priming can be ruled out (Kiefer 2005). If action representations contribute to object recognition, recognition performance is expected to be higher in the congruent than in the incongruent condition, demonstrating an action priming effect.
Experiment 1
Method
Participants
A total of 16 volunteers (6 males) were participated for payment. 15 participants were right-handed. The average age was 23 years (range 20–27). All participants were naive to the purpose of the experiments and were native German speakers. All had normal or corrected-to-normal vision and none had previously seen the stimuli.
Stimuli
We presented prime–target pairs comprised of action movies as primes and pictures of manipulable objects as targets. The prime stimuli consisted of eight gray-scale movie clips, each lasting 2,000 ms (25 frames/s). The movies showed hands performing an action in interaction with an unseen object. Movies were recorded using the MPI VideoLab (Kleiner et al. 2004). The actions were filmed in front of a black background. The actor wore black clothing. He performed the action in interaction with real objects in order to ensure that the dynamics of the action were correct which is not easily achieved when merely using pantomimes. The objects were painted black or covered in black cloth. Thereafter, luminance-based image thresholding was applied to each movie frame to segment the hands which performed the action from the unwanted “background” parts (actor, object, background). The size of the movie on the screen was 512 × 768 pixels (circa 18.8 × 25.3 cm) and subtended 11.9° × 17.8° at a viewing distance of 90 cm (a chin-rest was used to stabilize the observers’ viewing distance). We used the following eight actions as prime stimuli: (1) screwing with a screwdriver, (2) pounding with a hammer, (3) ironing with an electric iron, (4) typing on a computer keyboard, (5) rolling out with a rolling pin, (6) sweeping with a dustpan, (7) stapling with a stapler and (8) carrying a toolbox.
The target stimuli consisted of 56 gray-scale photographs of familiar man-made manipulable objects. The objects were inscribed into a square of 280 × 280 pixels in order to equate the maximal extension. Picture size on the screen was circa 10.3 × 10.3 cm (visual angle about 6.5° at a viewing distance of about 90 cm). Prime and target stimuli were presented in the center of a 21″ monitor with a resolution of 1,024 × 768 pixels and a refresh rate of 100 Hz.
Word labels in the picture–word matching task denoted the names of the objects at the basic level of abstraction (Rosch et al. 1976; e.g., “corkscrew”, “nutcracker”, “typewriter”, but note that we used German words as all participants were German native speakers). They were shown in white letters on black background in the center of the screen. Height of the word label was about 0.9 cm, width ranged between 2.6 and 9.7 cm (depending on word length). Thus, the visual angles ranged from about 0.57° × 0.95° to about 0.57° × 3.81°.
Procedure
Participants were instructed to fixate the central fixation cross and to initiate the next trial by pressing a button. After button press the fixation cross remained visible for 1,000 ms followed by a blank black screen for 700 ms. Then, a prime movie was shown (lasting 2,000 ms) followed by another blank black screen for 70 ms. Subsequently, the target object was displayed for 80 ms. The target object was replaced by a blank screen for 120 ms followed by a picture showing a word label (250 ms). Subjects were instructed to decide whether the word label matches the previously shown target picture and to respond as fast and as accurate as possible by pressing one of two buttons (button assignment counterbalanced across observers). After the response was recorded, the fixation point reappeared and the participant was able to initiate the next trial. The experimental session started with a short practice phase (10 trials, other stimuli than in the main experiment). The main experiment consisted of 2 blocks; in each block 56 stimulus pairs were presented.
Design
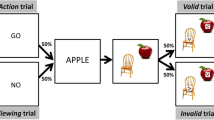
In the congruent condition, the eight prime movies were combined with several (3 up to 10, on average 7) target objects affording actions similar to the action shown in the movie. For example, the target objects scissors, nutcracker and pliers typically involve an action similar to the prime action “stapling with a stapler” in that they all have a typical hand movement in common: closing the hand to compress the handles. Overall, 8 prime actions were combined with 56 congruent target objects (examples are shown in Fig. 1).

Examples for prime–target pairs associated with congruent and incongruent typical actions. Stimuli are organized into action groups. Each group consists of a prime stimulus (short video clip showing hands performing an action) paired with several target objects that involve an action similar to the one displayed in the prime video clip (congruent action) and an identical number of objects that involve dissimilar actions (incongruent action). For example, the action displayed in the prime movie of action group 1, “rolling out with a rolling pin”, involves similar movements as the typical actions associated with the target objects of the congruent condition which is pushing a lawn mower, a wheelbarrow or a walker
Importantly, target objects were never the same object as the one which was used to record the prime action. Thus, even if a participant guesses the (deleted) object upon which the action was carried out, the same object never appeared as a target stimulus. For example, when viewing hands typing on an unseen computer keyboard it is easily possible that the observer guesses the object (keyboard) upon which the action is carried out. By avoiding to show these objects as targets we could rule out that a potentially observed “action priming” effect is, in fact, simply a priming effect of the pre-activated object representation on target recognition.
In the incongruent condition, the 56 target objects were randomly assigned to one of the 7 dissimilar prime actions such that each prime movie was combined with the same number of congruent and incongruent targets. This randomization was done once and was retained unchanged for all subjects (which enables us to equate congruent and incongruent prime–target pairs for semantic similarity; see below).
A total of 50% of the target pictures (randomly chosen for each observer individually) were combined with the word label correctly denoting the object, in both the congruent and the incongruent condition. On the other 50% of the trials the remaining word labels were randomly assigned to the target objects such that they did not match the target. The presentation order of prime–target stimulus pairs was randomized.
Norming studies
In two norming studies, ratings were obtained with regard to action similarity and semantic similarity in order to (1) ensure that in the congruent condition the similarity between prime action and the action participants typically associate with the target object is indeed significantly higher than in the incongruent condition and (2) to ensure that semantic similarity does not differ across congruent and incongruent conditions (to rule out a potential confound by global semantic similarity).
In the first norming experiment (action similarity), a prime movie and a target object were sequentially presented in every trial (same pairing and same procedure as in Experiment 1, see below). Prime–target pairs were presented in randomized order. Subjects (n = 11) had to judge the similarity between observed prime action and the action they typically associate with the target object on a scale from 1 to 7, where 1 indicates very low and 7 very high similarity. A two-tailed two-sample t test revealed that action similarity was significantly higher for congruent as opposed to incongruent prime–target pairs (incong. 2.41, cong. 6.00, P < 0.001) indicating that the experimental manipulation was effective (see Fig. 2).

Results of the norming studies. Left panel action similarity rating on a scale from 1 to 7 were 1 indicates low and 7 high similarity. Right panel rating of the semantic similarity between the object used to record the prime movie and the target object (on a scale from 1 to 7). Error bars represent the standard error of the mean across observers
In the second norming study (semantic similarity), a photograph of the object, which has been used to record the prime action, was presented before the congruent and incongruent target objects (same procedure as in the first norming study). Participants (n = 12) had to indicate the semantic similarity between the object used in the action movie and the target object (on a scale from 1 to 7, with 1 indicating very low similarity, 7 very high similarity). A two-tailed two-sample t test did not reveal significant differences of semantic similarity (incong. 4.58, cong. 4.64, P > 0.6) between prime–target stimulus pairs from incongruent and congruent conditions (see Fig. 2). This result renders it unlikely that a potential priming effect in the main experiments (1 and 2) is due to differences in global semantic similarity.
Results
The analysis was restricted to trials on which picture—word label pairing was correct—as processes underlying performance in incorrect picture–word trials are less constrained than in correct trials. Analysis of reaction time data was additionally restricted to trials on which the participants responded correctly to the task.
Matching accuracy was higher in the congruent than in the incongruent condition (cong.: mean acc. = 94.3%, incong.: mean acc. = 89.6%). A one-tailed paired-sample t test revealed a significant effect of action congruency [t(15) = 2,833, P < 0.01]. Reaction times did not differ significantly across conditions [cong.: mean RT = 416 ms, incong.: mean RT = 424, t(15) = −0,916, P > 0.18] (see Fig. 3 upper panels).

Performance in the picture-word matching task for prime–target pairs with congruent and incongruent actions. Left panels accuracy in percent correct responses. Right panels reaction times. Error bars represent the standard error of the mean across observers. Experiment 1 without masking of the target object. Experiment 2 with backward masking of the target object
In agreement with our prediction we found an action priming effect on matching accuracy—although we controlled for semantic similarity as a potential confounding factor. We did not observe an effect on reaction times. Importantly, reaction times are not faster in the incongruent condition and thus, the observed priming effect on accuracy does not merely reflect a speed-accuracy trade-off.
Accuracy in the picture–word matching task was on average at about 90%, and thus relatively high. Potentially, when the perceptual system is more taxed by masking the target object, action priming effects may become stronger and possibly evident also in the reaction times.
Experiment 2
Our aim in Experiment 2 was twofold. First, we wanted to replicate the action priming effect, and second, we assessed whether the action priming effect can be demonstrated also for reaction times when object naming is more demanding. For this reason we introduced a mask (42 ms) immediately after the target object in order to deteriorate viewing conditions and impose higher difficulty on the task through backward masking. We expected to find an action priming effect both for recognition accuracy and for naming latencies.
Method
A total of 16 volunteers (5 males) were participated in Experiment 2. They all were right-handed and the average age was 24 years (range 19–32). Procedure, task and design were the same as in Experiment 1, except that the target object was followed by a randomly selected mask presented for 40 ms in order to reduce prime visibility. Four masks were created by pasting image fragments of several target objects into a patchwork-like picture, and a mask was randomly selected in each trial.
Results
Matching accuracy was again higher in the congruent than in the incongruent condition (cong.: mean acc. = 93.9%, incong.: mean acc. = 87.3%). A one-tailed paired-sample t test revealed a significant effect of action congruency [t(15) = 3,252, P < 0.002]. Again, reaction times did not differ significantly across conditions [cong.: mean RT = 496 ms, incong.: mean RT = 506, t(15) = −0,552, P > 0.29] (see Fig. 3 lower panels). Again, there are no signs for a speed–accuracy trade-off.
The results of Experiment 1 were replicated and thus, it was confirmed that observing an action movie (prime) exerts a facilitatory effect on the recognition of a subsequently presented manipulable object typically involving a similar action. This indicates that action knowledge contributes to object recognition. Numerically, the action priming effect on error rate was somewhat larger than in Experiment 1 suggesting that the increased difficulty to identify the target object (as indicated by the increased average reaction times in Experiment 2 as opposed to Experiment 1) enhanced the influence of the prime movies. However, action priming effects did not generalize to reaction times. Possibly, the action priming as realized in the present experiments only facilitates accuracy, but not speed of object recognition. Alternatively, action priming effects may be found when the viewing conditions for the target object are further impaired.
General discussion
In two experiments, we found that observing an action sequence can prime the recognition of a subsequently presented manipulable object that typically involves a similar action. This finding indicates that action representations constitute part of the representation of manipulable man-made objects such as tools and musical instruments and play a functional role in object processing.
Although this action priming on picture-matching accuracy was significant in the by-subject analysis, it was not reliable in by-item analyses suggesting that only a limited amount of items contributed to the effect. Yet, a closer inspection of the results of the item analyses revealed that accuracy was at ceiling for about half of the target objects. As a consequence, the prime movie could not modulate object recognition performance for these items which is the most likely reason for the non-significance of the action priming effect in the item analyses.
It should be noted that in the action movies used as primes in our experiment the objects that were acted upon were erased and never the same as the target objects. Instead, target objects in the congruent condition were always different objects that only involve similar typical actions. Hence, we can rule out that the observed priming effect was simply due to a repetition of the object information inherent in prime and target stimuli. Furthermore, we carefully matched overall semantic similarity between objects used in the action movies and the target objects for the congruent and incongruent conditions so that semantic priming effects can also be excluded. Thus, even if participants had correctly guessed the object, which was involved in performing the prime action, non-action-related object knowledge could not contribute to the presently observed priming effects. Finally, our experimental design also rules out that the priming effect depends on the identity of action words related to the prime movie and the target objects because the actions demonstrated in the prime movies and the actions associated with the target objects were always different, but only showed a high action similarity based on movement similarity in the congruent condition (e.g., stapling with a stapler and cutting with a scissors). As global semantic similarity was matched, the target action even in the congruent conditions could not be more accurately predicted from the prime action than in the incongruent condition. Hence, we can safely conclude that the present action priming effect on object recognition is based on the similarity of the observed action and the action affordance of the target object.
Our results are in good agreement with the view that objects are represented in a distributed fashion in sensory and motor areas that code different types of knowledge about an object (e.g., how it looks like, how it moves, how to interact with it) (e.g., Martin et al. 1995, 2000; Kiefer 2001; Kiefer and Spitzer 2001; Weisberg et al. 2007; Hoenig et al. 2008). According to this view, an object is represented by a pattern of activation across the multiple subsystems where activity is relatively more pronounced in areas processing attributes more relevant to the object. Action-related information is particularly important for representing manipulable objects such as tools (e.g., Warrington and Shallice 1984; Warrington and McCarthy 1987; Farah and McClelland 1991; Sacchett and Humphreys 1992). Therefore, action knowledge may exert a facilitatory effect on recognition of manipulable objects (e.g., Chao and Martin 2000; Helbig et al. 2006).
It has been discussed whether action representation merely play an epiphenomenal role in the representation of manipulable objects, which are evoked by post-conceptual imagery or associative processes (Machery 2007; but see Kiefer et al. 2007; Kiefer et al. 2008). The presently obtained action priming effects rule out this possibility because they demonstrate the functional involvement of action representations during the course of object recognition: Imagery or associative processes can only be evoked after the concept is accessed and the object is fully recognized. As action representations already influence the object recognition process, they must be an integral part of the object representation rather being evoked at later processing stages.
How could the observed action priming effect be functionally mediated? Action observation and the execution of an action activate similar neural substrates as demonstrated by a number of neuroimaging (e.g., Rizzolatti et al. 1996b; Decety et al. 1997; Grèzes et al. 1998; Handy et al. 2003) and neurophysiological studies (e.g., Fadiga et al. 1995; Hari et al. 1998; Cochin et al. 1999). This suggests that the perception of an action sequence activates the corresponding motor representation (e.g., Rizzolatti et al. 1996a). It therefore seems likely that the observed priming effect is caused by the pre-activation of motor representations triggered by observing the prime action. Likewise, representations of manipulable objects strongly involve and interact with the motor system (Tucker and Ellis 1998, 2001; Glover et al. 2004; Craighero et al. 2008). Thus, it seems that in the present study and in a previous experiment (Helbig et al. 2006) action representations (matching the motor affordance of the target object) were activated by means of different prime stimuli (action movies vs. pictures of manipulable objects) and facilitate object recognition performance. However, it remains an open question which stage of the object recognition process is influenced by action representations. Action representations may already contribute to perceptual encoding, for instance by facilitating the activation of the appropriate structural descriptions (Humphreys et al. 1988). Alternatively, action representations could help to access the correct object concept through activating action-related conceptual features. This issue has to be addressed in future studies, e.g., by exploiting the high temporal resolution of event-related potential recordings.
In conclusion, the present study demonstrates that observing an action can facilitate the recognition of manipulable man-made objects that typically involve a similar action. This result indicates that action representations play a functional role in visual object recognition. The present study therefore further supports the notion of a functional interaction between the brain systems for object recognition and object-directed action.
Notes
Picture–word matching tasks are more constrained than naming tasks (as used in the previous study, Helbig et al. 2006), and are less susceptible to potential priming effects related to word labels (which may result from subjects’ attempts to imagine the names of objects with which the actions were performed). Moreover, they are considered to be better suited to study object recognition (see Jolicoeur and Humphrey 1998).
References
Boronat CB, Buxbaum LJ, Coslett HB, Tang K, Saffran EM, Kimberg DY, Detre JA (2005) Distinctions between manipulation and function knowledge of objects: evidence from functional magnetic resonance imaging. Cogn Brain Res 23:361–373
Chao LL, Martin A (2000) Representation of manipulable man-made objects in the dorsal stream. Neuroimage 12:478–484
Chao LL, Haxby JV, Martin A (1999) Attribute-based neural substrates in temporal cortex for perceiving and knowing about objects. Nat Neurosci 2:913–919
Cochin S, Barthelemy C, Roux S, Martineau J (1999) Observation and execution of movement: similarities demonstrated by quantified electroencephalography. Eur J Neurosci 11:1839–1842
Craighero L, Bonetti F, Massarenti L, Canto R, Fabbri Destro M, Fadigo L (2008) Temporal prediction of touch instant during observation of human and robot grasping. Brain Res Bull 75:770–774
Decety J, Perani D, Jeannerod M, Bettinardi V, Tadary B, Woods R, Mazziotta JC, Fazio F (1994) Mapping motor representations with positron emission tomography. Nature 371:600–602
Decety J, Grèzes J, Costes N, Perani D, Jeannerod M, Procyk E, Grassi F, Fazio F (1997) Brain activity during observation of actions influence of action content and subject’s strategy. Brain 120:1763–1777
Fadiga L, Fogassi L, Pavesi G, Rizzolatti G (1995) Motor facilitation during action observation: a magnetic stimulation study. J Neurophysiol 73:2608–2611
Farah MJ, McClelland JL (1991) A computational model of semantic memory impairment: modality specificity and emergent category specificity. J Exp Psychol Gen 120:339–357
Gerlach C, Law I, Gade A, Paulson OB (2002) The role of action knowledge in the comprehension of artefacts—a PET study. Neuroimage 15:143–152
Glover S, Rosenbaum DA, Graham J, Dixon P (2004) Grasping the meaning of words. Exp Brain Res 154:103–108
Graf M, Schütz-Bosbach S, Prinz W (2009) Motor involvement in action and object perception: similarity and complementarity. In: Semin G, Echterhoff G (eds) Grounding sociality: neurons, minds, and culture. Psychology Press, New York
Grafton ST, Fadiga L, Arbib MA, Rizzolatti G (1997) Premotor cortex activation during observation and naming of familiar tools. Neuroimage 6:231–236
Grèzes J, Decety J (2002) Does visual perception of object afford action? Evidence from a neuroimaging study. Neuropsychologia 40:212–222
Grèzes J, Costes N, Decety J (1998) Top down effect of strategy on the perception of human biological motion: a PET investigation. Cogn Neuropsychol 15:553–582
Grill-Spector K, Kanwisher N (2005) Visual recognition: as soon as you see it, you know what it is. Psychol Sci 16:152–160
Handy TC, Grafton ST, Shroff NM, Ketay S, Gazzaniga MS (2003) Graspable objects grab attention when the potential for action is recognized. Nat Neurosci 6:421–427
Hari R, Forss N, Avikainen S, Kirveskari E, Salenius S, Rizzolatti G (1998) Activation of human primary motor cortex during action observation: a neuromagnetic study. Proc Natl Acad Sci USA 95:15061–15065
Helbig HB, Graf M, Kiefer M (2006) The role of action representations in visual object recognition. Exp Brain Res 174:221–228
Hoenig K, Sim E-J, Bochev V, Herrnberger B, Kiefer M (2008) Conceptual flexibility in the human brain: dynamic recruitment of semantic maps from visual, motion and motor-related areas. J Cogn Neurosci 20:1799–1814
Humphreys GW, Riddoch MJ, Quinlan PT (1988) Cascade processes in picture identification. Cogn Neuropsychol 5:67–103
Jeannerod M (2001) Neural simulation of action: a unifying mechanism for motor cognition. Neuroimage 14:S103–S109
Jolicoeur P, Humphrey GK (1998) Perception of rotated two-dimensional and three-dimensional objects and visual shapes. In: Walsh V, Kulikowski J (eds) Perceptual constancy. Why things look as they do. Cambridge University Press, Cambridge, pp 69–123
Kiefer M (2001) Perceptual and semantic sources of category-specific effects: event-related potentials during picture and word categorization. Mem Cogn 29:100–116
Kiefer M (2005) Repetition priming modulates category-related effects on event-related potentials: further evidence for multiple cortical semantic systems. J Cogn Neurosci 17:199–211
Kiefer M, Spitzer M (2001) The limits of a distributed account of conceptual knowledge. Trends Cogn Sci 5:469–471
Kiefer M, Sim E-J, Liebich S, Hauk O, Tanaka JW (2007) Experience-dependent plasticity of conceptual representations in human sensory-motor areas. J Cogn Neurosci 19:525–542
Kiefer M, Sim E-J, Herrnberger B, Grothe J, Hoenig K (2008) The sound of concepts: four markers for a link between auditory and conceptual brain systems. J Neurosci 28:12224–12230
Kleiner M, Wallraven C, Bülthoff HH (2004) The MPI videolab—a system for high quality synchronous recording of video and audio from multiple viewpoints. Technical Report, Max Planck Institute for Biological Cybernetics 123:1–19
Machery E (2007) Concept empiricism: a methodological critique. Cognition 104:19–46
Martin A, Haxby JV, Lalonde FM, Wiggs CL, Ungerleider LG (1995) Discrete cortical regions associated with knowledge of color and knowledge of action. Science 270:102–105
Martin A, Wiggs CL, Ungerleider LG, Haxby JV (1996) Neural correlates of category-specific knowledge. Nature 379:649–652
Martin A, Ungerleider LG, Haxby JV (2000) Category specificity and the brain: the sensory/motor model of semantic representations of objects. In: Gazzaniga MS (ed) The Cognitive Neurosciences. The MIT Press, Cambridge, pp 1023–1036
Prinz W (1990) A common coding approach to perception and action. In: Neumann O, Prinz W (eds) Relationships between perception and action: current approaches. Springer, Berlin, pp 167–201
Rizzolatti G, Sinigalia C (2007) Mirrors in the brain: how our minds share actions, emotions, and experience. Oxford University Press, New York
Rizzolatti G, Fadiga L, Gallese V, Fogassi L (1996a) Premotor cortex and the recognition of motor actions. Cogn Brain Res 3:131–141
Rizzolatti G, Fadiga L, Matelli M, Bettinardi V, Paulesu E, Perani D, Fazio F (1996b) Localization of grasp representations in humans by pet: 1 observation versus execution. Exp Brain Res 111:246–252
Rosch E, Mervis CB, Gray WD, Johnson DM, Boyes-Braem P (1976) Basic objects in natural categories. Cogn Psychol 8:382–439
Sacchett C, Humphreys GW (1992) Calling a squirrel a squirrel but a canoe a wigwam: a category-specific deficit for artefactual objects and body parts. Cogn Neuropsychol 9:73–86
Tucker M, Ellis R (1998) On the relations between seen objects and components of potential actions. J Exp Psychol Hum Percept Perform 24:830–846
Tucker M, Ellis R (2001) The potentiation of grasp types during visual object categorization. Vis Cogn 8:769–800
Tucker M, Ellis R (2004) Action priming by briefly presented objects. Acta Psychol 116:185–203
Warrington EK, McCarthy RA (1987) Categories of knowledge. Further fractionations and an attempted integration. Brain 110:1273–1296
Warrington EK, Shallice T (1984) Category specific semantic impairments. Brain 107:829–854
Weisberg J, van Turennout M, Martin A (2007) A neural system for learning about object function. Cereb Cortex 17:513–521
Acknowledgments
This work was supported by the Max Planck Society and by the German Research Community (DFG Ki 803/1-1 and 803/1-3). We wish to thank Mario Kleiner for help with recording the action movies.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Helbig, H.B., Steinwender, J., Graf, M. et al. Action observation can prime visual object recognition. Exp Brain Res 200, 251–258 (2010). https://doi.org/10.1007/s00221-009-1953-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00221-009-1953-8